








こんにちは、fuyutsukiです。
PythonでWordCloud(ワードクラウド)を作成する方法について解説します。
日本語と英語でそれぞれやり方が異なるので注意が必要です。
例によって、必要な環境構築からPythonコードまで網羅的に解説します。
WordCloud実行の流れ
そもそもWordCloudとは
以下の画像のように、テキストデータの解析に使われます。
頻出単語を可視化することができ、トレンドの把握のツールとして使用可能です。
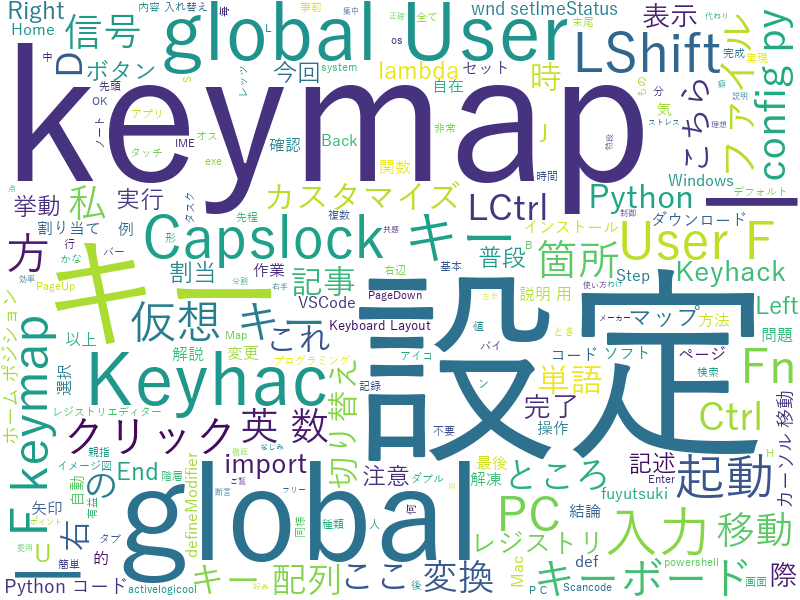
WordCloudを時系列で並べてトレンドの移り変わりを考察するというのも面白いですね。
投資にも役立つツールかと思います。
①テキストデータの用意
WordCloudを試すためには、何と言ってもまずはテキストデータを用意する必要があります。
②Pythonの仮想環境の構築
今回はwordcloudとjanomeをインストールします。
janomeは形態素解析のライブラリです。他に有名なものとしてMecabがあります。
形態素解析を行うことで、文章を単語毎に分割することができます。
まずは、以前記事で解説したように仮想環境を構築しておきましょう。
個人的におすすめしたいのは、virtualenvによる仮想環境構築の方法です。

記事で解説したバッチファイルをダブルクリックするだけで仮想環境構築が完了するので、まだチェックしていない方はぜひ見てみてください。
今回は以下のようなバッチファイルを作成しましょう。
@echo off
rem スクリプトが置かれている場所をカレントディレクトリにする。
cd /d %~dp0
rem 念のためvirtualenvのインストールとpipのアップグレードを行う。
pip install virtualenv
python -m pip install --upgrade pip
rem venvの環境を構築する。
python -m venv venv
call ./vENV/Scripts/activate
python -m pip install --upgrade pip
rem 各パッケージをインストール
pip install wordcloud
pip install janome
pausePythonコードの全容
早速ですが、下記のコードでWordCloudを行うことができます。
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
# txtファイルからデータの読み込み
with open('keyhack.txt', 'r', encoding="utf-8") as text_file:
txt = text_file.read()
# janomeによる形態素解析
word_dic = {}
# テキストを一行ごとに処理
lines = txt.split("\r\n")
for line in lines:
malist = Tokenizer.tokenize(line)
for w in malist:
word = w.surface
part_of_speech = w.part_of_speech # 品詞
if part_of_speech.find("名詞") < 0: continue # 名詞だけをカウント
if not word in word_dic:
word_dic[word] = 0
word_dic[word] += 1
# 頻出単語を表示
keys = sorted(word_dic.items(), key = lambda x:x[1], reverse=True)
for word, cnt in keys[:1500]:
print("{0}({1})".format(word,cnt),end="")
# タイトルの名詞のみをスペース区切りのテキストへ変換
words_list = []
for i in lines:
tokens = Tokenizer().tokenize(i)
# 必要ない単語を設定
stop_words = ['-', '(', ')', '/', 'こと', '1', 'ため', '.', 'よう', '以下']
for token in tokens:
# 品詞を抽出
token_list = token.part_of_speech.split(',')[0]
# 品詞から名詞だけ抽出
if token_list in ['名詞']:
# 必要ない単語を省く
if token.surface not in stop_words:
words_list.append(token.surface)
text = ' '.join(words_list)
# 日本語フォントの指定
fpath = "C:/Windows/Fonts/YuGothM.ttc"
# ワードクラウドの各種設定指定
wordcloud = WordCloud(background_color="white", #背景を白に
font_path = fpath, width = 800, height = 600).generate(text)
wordcloud.to_file("./wordcloud_keyhack.png")Pythonコードの解説
①テキストファイルの読み込み
下記がテキストファイルの読み込みとなります。
予期しないエラーを防止するため、ただ読み込むのではなくwith open構文を使用することを推奨ですね。
# txtファイルからデータの読み込み
with open('keyhack.txt', 'r', encoding="utf-8") as text_file:
txt = text_file.read()②janomeによる形態素解析の後に頻出単語を表示
janomeによる形態素解析の後で頻出単語を表示するまでがこちらになります。
 Fuyutsuki
Fuyutsuki他の人に共有する際にはWordCloudにより出力した画像を渡しますが、自分のために頻出単語を確認する用途であればこちらのコードの方を重宝しています。
# janomeによる形態素解析
word_dic = {}
# テキストを一行ごとに処理
lines = txt.split("\r\n")
for line in lines:
malist = Tokenizer.tokenize(line)
for w in malist:
word = w.surface
part_of_speech = w.part_of_speech # 品詞
if part_of_speech.find("名詞") < 0: continue # 名詞だけをカウント
if not word in word_dic:
word_dic[word] = 0
word_dic[word] += 1
# 頻出単語を表示
keys = sorted(word_dic.items(), key = lambda x:x[1], reverse=True)
for word, cnt in keys[:1500]:
print("{0}({1})".format(word,cnt),end="")③WordCloudの実行
最後にWordCloudの実行のコードになります。
画像に必要ない単語を設定することもできます。
token.surfaceで単語そのままを、token.part_of_speech.split(‘,’)[0]で単語の品詞を抽出しています。
品詞を英語にするとpart of speechなのでそこから来ていますね。
# タイトルの名詞のみをスペース区切りのテキストへ変換
words_list = []
for i in lines:
tokens = Tokenizer().tokenize(i)
# 必要ない単語を設定
stop_words = ['-', '(', ')', '/', 'こと', '1', 'ため', '.', 'よう', '以下']
for token in tokens:
# 品詞を抽出
token_list = token.part_of_speech.split(',')[0]
# 品詞から名詞だけ抽出
if token_list in ['名詞']:
# 必要ない単語を省く
if token.surface not in stop_words:
words_list.append(token.base_form)
text = ' '.join(words_list)
# 日本語フォントの指定
fpath = "C:/Windows/Fonts/YuGothM.ttc"
# ワードクラウドの各種設定指定
wordcloud = WordCloud(background_color="white", #背景を白に
font_path = fpath, width = 800, height = 600).generate(text)
wordcloud.to_file("./wordcloud_keyhack.png")まとめ
今回の記事では下の画像のように日本語及び英語のWordCloudを作成する方法を解説しました。
日本語では、英語と違ってスペースのような区切りがないため、形態素解析が必要となります。
このように、私はPythonを普段から触っています。Pythonの独学には買い切り型のオンライン動画学習サービスUdemyに大変お世話になりました。
もし興味がある方はこちらの記事を併せてチェックしてみてください。頻繁に講座のセールが行われているので、気になる講座はセール中に購入しましょうね!

自分に合っている勉強スタイルをいち早く見つけることが最終的には大切です。
独学でプログラミング学習をするなら、まずおすすめしたいのがUdemyです。オンライン動画買い切り形式で、実務レベルのスキルを習得できます。定期的に80~90%OFFセールが実施されていますよ。
\ セール中は80~90%OFFで購入可能/
30日間返金保証
最後まで読んでいただきありがとうございました。ではまた、次の記事で!
コメント